A visual book recommender
Introduction
I have this long running conjecture that used book stores are superior to commercial book outlets (including Amazon) for discovering books. One of the reasons for this I think has less to do with a skewed explore/exploit strategy, and more to do with the way exploratory suggestions are sourced. I think financial pressure skews exploratory search suggestions towards oversampling newer books rather than older adjacent books. I get that though; oversampling newer books is a simple way to help combat the rich getting richer trap. The problem is that I’m biased against new books; I think they’re mostly noise. Used books stores on the other hand are curated by humans for other humans (who probably live nearby). If I ask for a book that’s like “x” they’re not going to point me to the newer version of “x”, they’re going to show me books “y” and “z”. There are additional reasons that go beyond just oversampling newer books which I’ll touch on later. I’ll also admit that all the supporting evidence I have is completely anecdotal, but still, when I want a new book I don’t pull out my phone, I walk down the street to the used book store.
First attempt
I’ve been casually thinking about how a book recommender could reflect the used book store experience for a while now. This first attempt is still a bit rough around the edges, but I think it captures some of what I’m after. It initially started out as roughly 100M book reviews that were then distilled into basic reading preferences. I then rode the Pareto frontier between latent representation and model accuracy for about a month before I landed on what you see below. Books closer together indicate a stronger favorability. Enjoy! (make sure to go click the full screen button)
Genre clusters
I think one of the key drivers fueling the high discovery rate at used book stores has to do with the layout. All of my favorite used book stores are located in old buildings that have lots of nooks and crannies. It’s this fractal approach to book layout that I think encourages exploration into areas you wouldn’t explicitly seek out otherwise. This “nooks and crannies” feeling was a major attribute I was trying to recreate with this first iteration.
Below, you’ll find a selection of the most common genres. Each book and its assigned genre are represented once as a single point. Keep in mind that the model has absolutely no understanding of authors, genres, book descriptions, vocabulary, or plot lines. It simply knows which books people liked more than others. Each cluster represents a collection of books which have a higher than expected favorability amongst a subset of readers. A large genre such as Science-fiction can include many clusters each representing a different pocket of interest within that genre. A genre that consists of one cluster with sharp, well defined borders (such as Romanian-literature or Christian-fiction) indicates a readership with more focused interests.
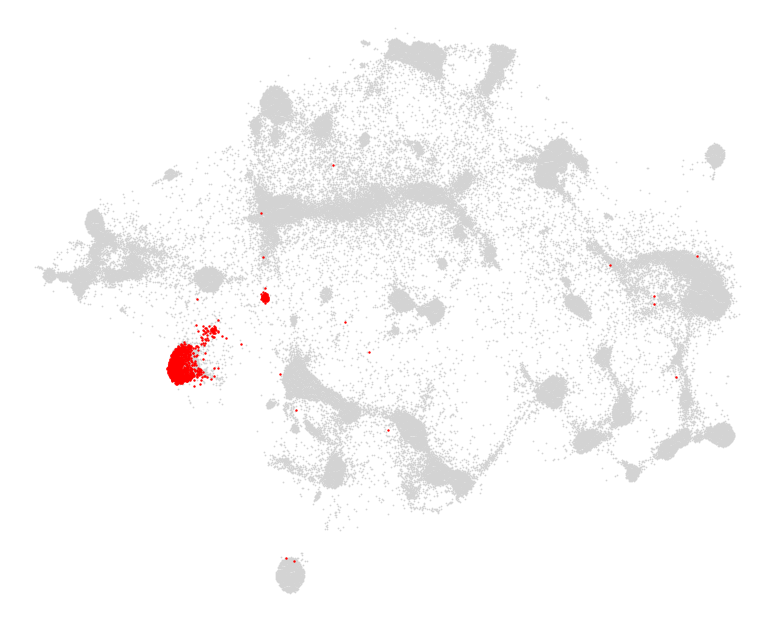
In most clustering situations, crisp, well defined borders are the desired outcome. Points which fall outside of these boundaries are usually seen as a nuisance (customer segmentation amiright?). In this particular situation though, the books which fall between multiple clusters actually represent something rather interesting. They’re books that strongly capture multiple readerships (or they capture a smaller, more diffused readership).
Technical details
A few years ago, I scraped a little over 100M book reviews spread across 505k unique users and 6.97M books. In order to reduce the potential influence of spam reviews I took the following measures:
- Only include books with 100 reviews or more.
- Only include reviews which came from users who had at least 10 reviews.
- Only include users who had reviews spread across a minimum time window of 6 months.
After filtering, the total review count dropped down to 26.8M across 396k users and 59k books. Since many of these books were in fact just different editions of the same book, they were consolidated into their canonical version represented by the edition with the most reviews. This brought the final count to 51,847 books.
The model itself is just a basic siamese network with a contrastive loss. I had initially implemented a triplet loss which yielded good model performance but the embeddings lacked the aesthetic qualities I was after. After some tinkering, I ended up simplifying it down to the pairwise contrastive loss you see below:

We can clearly see that this loss contains two distinct forces trying to overcome each other. If we establish d as the euclidean distance between the latent representations of two books xi and xj, then y=0 represents two books in close proximity with each other while y=1 are two books further apart. With the bounds established, the forces become apparent.

With these two competing forces shuffling books around, the next question becomes: how do we want to define similarity? I actually tested about a dozen different strategies and ended up using the pointwise mutual information shared between books.

High PMI scores are produced when the joint probability of liking two books a and b exceeds the expected probability of liking those same two books assuming independence. Now it’s just a matter of computing these distributions, but in order to do so we now need to define like and dislike… Well I hate to disappoint:

Not only was this the very first thing I tried, and after testing maybe twenty variants (this includes model training too!) it was still producing the best embeddings. I know, what a letdown… Now the original question of similarity can be resolved with the following:

With everything defined, the filtered 26.8M reviews were expanded into just over 300M pair-wise training rows. Each book was represented by a one-hot encoded array (1x51847) and compressed into a 64D latent space by the model. To further accentuate the clusters, instead of running through each training row per epoch, I sampled rows proportional to the combined (book a + book b) review count frequency. After model training, the 64D book vectors were further compressed down to 2D via t-SNE. The output of which can be seen below.

Because t-SNE doesn’t care about overlapping points I needed a way to both remove the overlap and add some padding around the book covers. The script I wrote to accomplish this iteratively moves the book covers while also producing these oddly satisfying animations…

Thoughts on v2.0
My favorite books fall within the intersection of engineering and adventure. Not “engineering” as a subject, but rather from the perspective of the engineers. My favorite book of all time, Skunkworks by Ben Rich captures this beautifully. The fact that Skunkworks hasn’t been made into a movie in the style of the The Big Short blows my mind. Anyway, books like Apollo (Charles Murray & Catherine Cox), The Descent (Brad Matsen), The Fastest Men on Earth (Paul Clifton), and The First Crossing of the Polar Sea (Roald Amundsen) are other great books in this area. But since aerospace engineering doesn’t have a whole lot of overlap with deep sea exploration, I never get served these recommendations online. Thank goodness for The Ohio Book Store!
Anyway, I’ve been experimenting with the idea of long tail book recommendations and fuzzy vectors and the initial results have me really excited. I just want more serendipitous book suggestions!